글의 목표
1. 가설검정이 무엇인지 직관적으로 이해할 수 있다
2. 검정통계량이 왜 도입됐는지 그리고 무엇인지를 이해할 수 있다.
3. 귀무가설, 대립가설에 대한 정확한 정의를 알 수 있다.
4. p-value, 유의수준, 임계값에 대한 정확한 개념을 이해할 수 있다.
5. 최종적으로 가설검정에 있어 위의 용어들이 어떻게 매핑되고 사용되는지 알 수 있다.
가설검정이란?
통계학에서의 가설검정은 모집단(전체 집단)에 대한 어떤 주장(가설)을 세우고, 표본(부분 집단)을 관찰하여 그 주장이 맞는지 틀린지 판단하는 방법이다.
본론 (스토리 : 평균치 검정 One-sample t-test 예시)
* 요약된 결론만 보고싶다면 마지막, 결론만 봐도 된다 *
위에서 정의한 가설검정이 무엇인지 직관적인 그림으로 한 번 나타내보도록 하자.

그림 설명
구체적인 스토리로 예를 들어보자. 내가 어떤 집단의 평균나이를 짐작하건데 대략 70정도로 보인다. 그런데 해당 집단의 사람이 너무 많아서 모두 조사하는 것은 불가능하다. 나의 주장(가설)이 진짜인지 알아보기 위해 표본 30명을 추출해서 모평균의 추정량인 표본평균을 구해보았다. 결과적으로 표본 평균이 68이 나왔다.
(Q1) 표본의 데이터가 가설과 맞지 않다고 하여 가설이 틀린건가?
표본평균이 68이 나왔다 하여 과연 위의 가설이 틀렸다고 할 수 있겠는가? 실제로 모평균이 70일지도 모르는데?
- 아니다. 같은 절차를 수행을 하더라도 결과가 다르게 나올수 있는 불확실성 또는 변동성(통계량으로는 분산)이 존재하기 때문에, 표본평균이 68이 나왔다고해서 모평균이 70이 아니다라고 단정할 수는 없다.
(Q2) 나의 주장이 맞는지 표본으로 검증을 어떻게 할건데? (가설검증을 어떻게 할건가?)
검정통계량의 의의
표본 평균이 다를 수도 있고 같을 수도 있다고 한다면, 표본평균으로 어떻게 가설 검정을 할 수 있을지 의문이 생길 수 있다. 이때 도입되는 것이 바로 검정통계량의 분포를 통한 판단이다.
검정통계량이란?
표본 평균과 같은 표본 데이터를 이용해 모집단에 대한 가설을 검증하기 위해 계산되는 수치적 지표 (통계량)
위의 평균에 대한 가설에 알맞는 검정통계량을 정의해보자.

표본 평균에서 가설(평균)을 뺀 항을 분자에 둠으로써 가설 평균과 차이가 없을수록 0, 차이가 있을수록 0에서 멀어질 것이다. 즉, 평균 검정에서 사용되는 검정통계량은 가설 평균과의 거리로 정의됨으로써, 표본 평균이 가설 평균과 얼마나 다른지를 수치적으로 측정하여, 이러한 차이가 통계적으로 유의미한지를 평가하는 데 중요한 역할을 한다.
*통계적으로 유의미 하다라는 말은 뒤에서 다시 한 번 정리한다.
(Q3) 불확실성/변동성(분산)은 어디에 사용되는가?
검정통계량의 분포와 가설검정의 의의
위에서 불확실성 또는 변동성(통계량으로는 분산)이 존재하기 때문에 표본평균이 가설평균과 다르다고 해도 섣부르게 단정지을수 없다며, 그런데 검정통계량 자체는 그냥 표본 평균과 가설 평균의 거리 또는 유사한정도를 수치화 한것 뿐이잖아. 여기에는 어디에도 분산이란 개념이 들어가지 않는데? 어떻게 검정통계량만으로 가설 검정을 한다는거야?
질문 대답 요약
여기서 가설 검정의 핵심이 드러난다. 검정통계량은 가설 평균과의 거리를 수치화할 뿐만 아니라, 이 거리의 유의미성을 평가하기위해 검정통계량의 분포를 이용하여 통계적으로 유의미한 차이를 판단하는데 사용한다. (이 말이 와닿지 않을 거라 생각한다 아래 구체적인 예를 들어본다)
요약에 대한 설명 (중요)
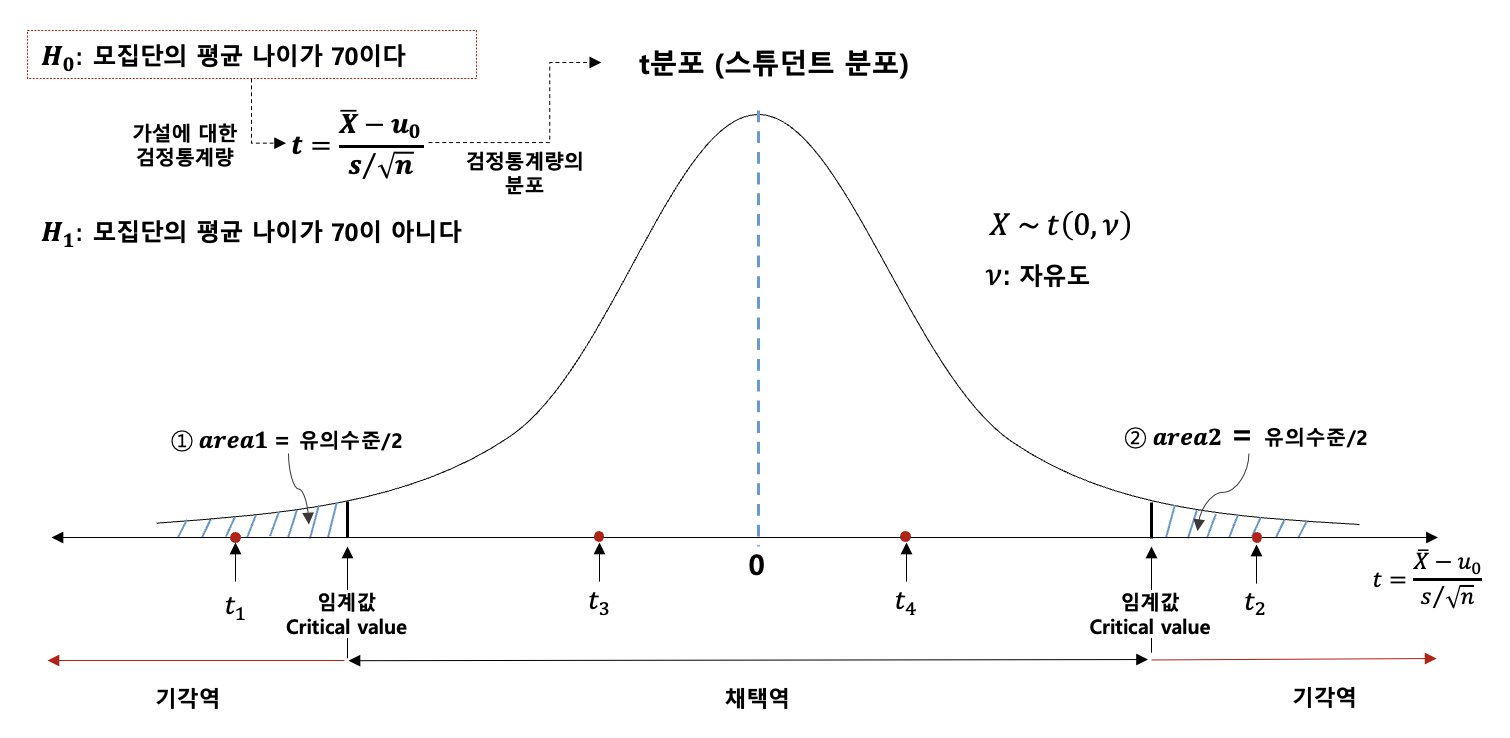
구체적인 예를 들어보자. 우리는 평균 가설에 대한 평가를 하기 위해 식(2)와 같은 검정통계량을 정의하였다. 또한 해당 검정통계량은 t분포(스튜던트 분포)를 따른다는 것은 수학자/통계학자들이 이미 증명해놓았다.

검정통계량이 위의 t분포를 따른다는 말을 위의 그림에 대입해서 다시 한 번 풀어 설명해보겠다.

가설검정의 의미 설명 (그림4 설명)
내가 모집단으로부터 표본을 4개 뽑았다고 해보자. (위의 그림상 표본1부터 표본4까지)
해당 표본들의 검정통계량을 구해보면 위의 그림상 t1 ~ t4까지가 된다. 검정통계량 t는 스튜던트 t 분포를 따르기 때문에, 추출된 표본은 높은 확률로 0 근처에 위치할 것이며, 극히 낮은 확률로 양 끝(그림상 area1, area2)에 존재할 가능성이 있다. 따라서 표본3, 표본4는 높은 확률에 의해 추출된 표본이며, 표본1과 표본2는 낮은 확률에도 불구하고 추출된 표본이다.
해석 포인트 (이해의 포인트)
위의 검정통계량은 가설 모평균과 표본 평균의 차이를 나타내고 있다. t3(표본3), t4(표본4)는 일반적인 분포(가설 모평균 - 표본평균 ≈ 0 근처)에서 추출된 표본임을 알 수 있다. 이를 통해 위의 표본3과 4는 모평균과 표본 평균의 차이가 0에 가깝다고 해석할 수 있다. 반면, t1(표본 1)과 t2(표본 2)는 극단적인 확률을 통해 추출된 표본이므로, 이들은 가설 모평균과의 차이가 큰 값 (가설 모평균 - 표본평균 ≈ 0 과 멀어짐) 을 가지므로 가설 모평균과의 거리가 멀어진다.
이를 정리하면, t3와 t4는 모평균과의 차이가 크지 않아 가설을 지지하는 경향이 있는 반면, t1과 t2는 모평균과의 차이가 커서 가설에 반하는 표본으로 해석될 수 있다.
극단적인 확률로 발견된 표본(t1, t2)은 해당 모집단에서 거의 발생할 가능성이 없으므로, 이러한 표본이 나타날 경우 해당 가설은 틀렸다고 판단할 수 있다. 이를 가설을 기각한다 라고 표현한다. 반대로 일반적인 활률분포 상에서 발견될 경우(t2, t3) 해당 가설이 맞다고 판단할 수 있다. 이를 가설을 채택한다 라고 표현한다.
이제야 귀무가설, 대립가설, 채택역, 기각역, 유의수준, 임계값, p-value에 대한 용어를 정의하여
가설검정을 정리할 수 있다.

1. 귀무 가설 (H0 : Null Hypothesis)
우리가 모집단(전체 집단)에 대해 세운 가설을 의미한다 (예제의 '평균 나이가 70일 것이다')
2. 유의 수준 (α : Significance Level)
어떤 가설을 채택하거나 기각할 기준이 되는 확률을 의미한다. (예제의 area1 + area2 확률 영역 = 가설 기각할 영역)
= 유의수준의 확률영역에서 표본의 검정통계량이 발견되었을때, 해당 가설을 기각하게 된다.
확률론에는 100%맞다고해서 가설을 채택하거나 100%틀려서 가설을 기각하는 것이 아니다. 발생할 확률이 높고 낮음을 가지고 가설을 채택하고 기각하는 것이다. 그렇기에 기각과 채택의 기준이 되는 확률을 정해야 한다.
어떠한 가설을 기각하고 채택함에 있어 기준이 될 확률은 분야마다 다르다. 예를 들어 자연과학에서는 유의 수준으로 0.01을 잡기도 하며, 인문 분야에서는 0.05로 잡기도 한다. 예를 들어 유의수준을 0.05로 잡는다면, 위의 그림상 파란색영역 (area1 +area2)이 0.05가 된다. 그럼 당연히 나머지 영역은 1-α =0.95가 된다. (위의 전체 영역의 넓이는 1이므로)
정리하자면, 표본의 검정통계량(가설에 대한)이 일반적인 95%이내에 들어오면, 해당 가설은 채택되며, 5%의 극한 확률 영역에서 발견되면, 일반적이지 않다 판단하여 가설을 기각하게 된다.
3. 기각역 (Critical Region)
검정통계량 분포에서 해당 가설이 기각이 되는 확률영역(범위)을 기각역이라 한다.
4. 채택역 (Acceptance Region)
검정통계량 분포에서 해당 가설이 채택 되는 확률영역(범위)을 기각역이라 한다.
5. 임계값 (Critical Value)
유의수준 영역의 경계가 되는 검정통계량(t)값을 임계값이라 한다.
이후 내가 뽑은 표본이 해당 임계값을 넘어서느냐 아니냐에 따라 가설 채택여부를 판단할 수 있다.
예제에서 t1부터 t4까지의 검정통계량을 가지고 표본4개에 대해서 판단해보도록 하자.
- 표본1 : t1은 기각역에 존재한다. 임계값 boundary 밖에 있다. 5%확률이하로 일어날 경우가 발생했다 - 기각
- 표본2 : t2는 채택역 안에 존재한다. 임계값 boundary 안에 있다. 95%확률로 일어날 경우가 발생했다 - 채택
- 표본3 : t3은 채택역 안에 존재한다. 임계값 boundary 안에 있다. 95%확률로 일어날 경우가 발생했다 - 채택
- 표본4 : t4는 기각역에 존재한다. 임계값 boundary 밖에 있다. 5%확률이하로 일어날 경우가 발생했다 - 기각
6. p-value (Probability Value)
p-value는 귀무 가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 같거나 더 극단적인 통계치가 관측될 확률을 의미한다.
(참고로 귀무 가설이 맞다는 전제 하에라는 말을 사용하는 이유는 우리는 귀무 가설하에 검정통계량을 정의했고 그에 대한 분포하에 가설검정을 하는 거기때문이다)

실제로 관측된 통계치 t1과 t2를 기준으로 p-value를 설명해보자.
- t1이 발생한 케이스와 같거나 더 극단적인인 통계치가 발견될 확률은 ①영역(빨간색 영역)을 의미한다. 이때의 영역 크기를 표본1 (t1)에 대한 p-value(확률)이라 한다.
- t2가 발생한 케이스와 같거나 더 극단적인 통계치가 발견될 확률은 ②영역(빨간색 영역)을 의미한다. 이때의 영역 크기를 표본2 (t2)에 대한 p-value(확률)이라 한다.
p-value를 통한 가설 채택/기각
p-value로 어떻게 채택/기각을 판단은 p-value와 유의수준을 비교함으로써 가능하다.
예를 들어 t1의 경우 0.013이고 t2의 경우 0.018라고 해보자. t1의 p-value는 0.05(유의수준)/2 = 0.025보다 작으므로 기각역에 존재할 것이므로 해당 가설을 기각할 수 있다. t2 또한 마찬가지 논리로 해당 가설을 기각할 수 있다.

위와 마찬가지로 실제로 관측된 통계치 t3과 t4를 기준으로 p-value를 설명해보자.
- t3이 발생한 케이스와 같거나 더 극단적인인 통계치가 발견될 확률은 ③영역(빨간색 영역)을 의미한다. 이때의 영역 크기를 표본3 (t3)에 대한 p-value(확률)이라 한다.
- t4가 발생한 케이스와 같거나 더 극단적인 통계치가 발견될 확률은 ④영역(빨간색 영역)을 의미한다. 이때의 영역 크기를 표본4 (t4)에 대한 p-value(확률)이라 한다.
p-value를 통한 가설 채택/기각
예를 들어 t3의 경우 0.2이고 t4의 경우 0.25라고 해보자. t3의 p-value는 0.05(유의수준)/2 = 0.025보다 크므로 채택역에 존재할 것이고 해당 가설을 채택할 수 있다. t4 또한 마찬가지 논리로 해당 가설을 채택할 수 있다.
7. 대립 가설 (H1 : Alternative Hypothesis)
이 가설은 귀무가설처럼 검정을 직접 수행하기는 불가능하며, 가설은 직접 귀무가설을 기각함으로써 받아들여지는 가설이다.
여태까지 귀무 가설을 채택하느냐 기각하느냐에 초점을 맞췄었다. 더 나아가 생각해보면, 귀무 가설을 기각했을 경우 결론은 무엇인가?라는 의문이 떠오르게 된다.
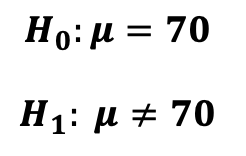
위에서 취급했던 예제는 귀무 가설을 기각함으로써 평균이 70이 아니다라는 대립 가설(주장)을 더 지지한 것이다.

그러나, 대립가설은 '평균이 70이 아니다'라는 형태일 수도 있지만, '평균이 70보다 크다' 또는 '평균이 70보다 작다'와 같이 구체적으로 설정할 수도 있다. 이에 따라 검정의 방식과 검정통계량의 해석이 달라지며, 양측검정(two-sided test)인지, 단측검정(one-tailed test)인지에 따라 p-value 계산 방법도 달라지게 된다.
양측검정과 단측검정에 대한 설명은 다음에 따로 포스팅하도록 하겠다. 이번 포스팅에서는 귀무가설을 기각함으로써 반증할 수 있는 대립가설이 항상 쌍으로 함께 고려되어야 함을 강조하고자 한다.
* 참고 (실제 스튜던트 분포)

t분포는 그림2와 같이 생겼으며, 자유도가 높아질수록, 데이터 표본이 클수록 표준 정규분포를 따른다는 것을 알 수 있다. 사실상 t분포는 표준정규분포와 거의 비슷하게 생겼으며, 둘의 차이는 표준화한 factor(분모)가 모분산이냐 표본분산이냐의 차이밖에 없다.
(Q4) 잘못 채택하거나 잘못 기각하는 경우는 없는가? (1종 오류, 2종 오류)
위에서 표본의 검정통계량(가설에 대한)이 일반적인 95%이내에 들어오면, 해당 가설은 채택되며, 5%의 극한 확률 영역에서 발견되면, 일반적이지 않다 판단하여 가설을 기각하게 된다.
가설검정의 핵심을 이렇게 설명할 수 있는데, 그렇다면 '실제로 가설이 맞는데도 불구하고 표본이 공교롭게 5%의 극한 확률 영역에 속해 가설이 기각되는 경우가 있을 수 있지 않은가?'라는 의문이 드는 것은 자연스럽고 당연한 일이다.
맞다. 위와 같이 가설이 잘못 기각될 확률이 있다. 이러한 경우를 1종 오류(Type I Error)라고 한다. 1종 오류는 실제로 귀무가설이 참임에도 불구하고 귀무가설을 기각하는 오류를 의미한다. 일반적으로 이 오류의 확률은 유의수준(α)으로 설정되며, 많은 경우 5%로 설정한다.
반대로, 실제로 대립가설이 참임에도 불구하고 귀무가설을 채택하는 경우도 존재한다. 이를 2종 오류(Type II Error)라고 하며, 이 오류의 확률을 β로 나타낸다. 결과적으로, 통계적 가설검정에서는 이러한 1종 오류와 2종 오류의 가능성을 항상 염두에 두어야 한다.
결론 (요약)
본론의 설명이 길었다. 아무래도 내가 이해하고 있는 것들을 전부 글로 녹여내는 작업은 쉽지 않았다. 결론으로 가설 검정 한 판 정리를 해보도록 한다.
가설 검정이란?
가설 검정은 모집단에 대해 가설을 세우고, 표본을 추출하여 이를 관찰함으로써 해당 가설이 맞는지를 판단하는 과정이다.
검정 통계량의 의의
먼저, 가설을 세우는데, 이 가설을 귀무가설(null hypothesis)이라고 한다. 이후, 귀무가설을 평가하기 위해 이를 대표할 수 있는 검정통계량을 정의하고, 해당 검정통계량의 분포를 그려낸다.
검정 통계량분포를 통한 가설검정의 의의
그리고, 표본을 통해 검정통계량을 구한다. 이 표본의 검정통계량이 분포 내에서 일반적인 95% 이내의 범위에 속하면 해당 가설을 채택하고, 5%의 극한 확률 영역에 속하게 되면 일반적이지 않다고 판단하여 가설을 기각하게 된다.
이때, 5%와 같은 극한 확률의 영역을 유의수준(α, significance level)이라고 하며, 그 경계값을 임계값(critical value)이라 한다. 또한, p-value라는 개념이 존재한다. 이는 특정 표본이 관찰될 확률이나 그보다 더 극단적인 값이 나올 확률을 의미한다.
[귀무 가설을 기각하거나 채택할 수 있는 지표 두 가지]
- 검정통계량을 통한 판단: 표본의 검정통계량이 임계값 밖에 위치할 경우 귀무가설을 기각한다.
- p-value를 통한 판단: p-value가 유의수준(α)보다 작을 경우 귀무가설을 기각한다.
대립 가설이란?
귀무 가설이 기각될 경우 반증되어 채택되는 가설을 대립 가설(alternative hypothesis)라고 한다. (대립 가설에 따라 검정통계량의 해석이 달라진다 : 양측 검정, 단측 검정)
1종 오류 및 2종 오류
실제로 귀무 가설이 참임에도 불구하고 표본이 공교롭게 5%의 극한 확률 영역에 속해 귀무 가설이 기각되는 경우가 있을텐데 이런 오류를 1종 오류라고 한다. 반대로 대립 가설이 참임에도 불구하고 귀무 가설이 채택 되는 경우를 2종 오류라고 한다.
이와 같이 가설 검정은 표본 데이터를 바탕으로 귀무가설의 타당성을 평가하는 과정이며, 이를 통해 모집단에 대한 특정 가설에 대해 결론을 내리게 된다.
참고 문헌
2. MiniTab 공식문서
3. Wiki백과 (정의 참고)
4. 통계학 입문 - 자유아카데미 (전공서적)
5. 학교 수업 자료 - 자료분석개론 (전공 수업)
6. 나의 생각 및 글 정리 (feat GPT)
'데이터분석-통계 > 통계학의 본질 이론' 카테고리의 다른 글
| 중심극한 정리 (Central Limit Theorem) : 정의 및 실험 & 용도 (2) | 2024.11.03 |
|---|---|
| 평균치 검정 : t검정 [One, Two(Student's & Welch's), Paired Samples t-test] (0) | 2024.11.03 |
| 신뢰 구간(Confidence Interval)의미와 직관 그리고 오해 : 구간 추정, 신뢰 수준, 오차 한계, 신뢰도 95%의 개념 (5) | 2024.10.13 |
| 자유도(Degree Of Freedom)란 & 모분산 추정과 자유도 (n-1) (1) | 2024.09.30 |
| 불확실성, 변동성, 분산 (feat 확률의 본질) (0) | 2024.09.30 |



