여담
최근 데이터분석 플랫폼을 만들면서 2019년, 2020년 학부 인턴과 대학원 시절에 했었던 데이터 분석을 다시 한 번 상기시키면서 정리하는 글입니다. 또한 기존에 잘 알지 못했던 자유도 개념을 정리하는 글입니다.
글의 목표
이번 포스팅에서는 모수통계학에서의 모분산 추정과 자유도 관련해서 얘기해보고자 한다.
이번 글을 읽고나면 이해가 가야할 포인트를 다음과 같이 정리할 수 있다.
1) 자유도의 개념
2) 표본에서의 모집단 분산 추정량에서 n-1로 나누는 이유
- 과소추정량의 관점의 설명
: n-1로 나눈 이유를 모집단 분포에서의
- 자유도의 관점의 설명 (분산에 대한 본질적 의미의 이해)
: 표본에서의 분산 추정량에서 자유도로 나눈 이유와 그에 대한 본질을 이해할 수 있다
본론
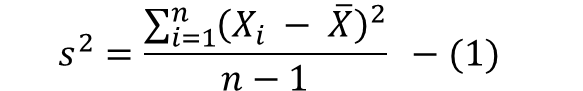

위의 수식1과 수식2는 각 각 표준편차의 분산(모분산 추정)과 모분산을 나타내고 있다.
분산 또는 표준편차 관련한 개념은 직관적으로 다음과 같이 해석할 수 있다.
0) 불확실성 정도를 표현하기 위함
- 같은 시행을 할때마다 불확실성에 의해 다른 결과가 나타나는 것을 수치화하기 위함.
1) 평균으로부터 각 데이터의 떨어져 있는 평균 거리
- 불확실성을 나타내기 위해 집단을 대표하는 평균값으로부터 데이터들이 얼마만큼 떨어져있는지 거리로 표현함
2) 표본 평균에 대한 정밀도 또는 설명력이라고 말 할 수 있다. (함의)
여기서부터는 혼자 했었던 의문을 던지면서 스토리를 이어가겠다.
1. n-1로 나누는 이유
분명 편차 또는 분산은 물리적으로 distance(거리)개념인데, 표준편차의 분산 추정은 표본의 개수(n)로 나누는 것이 아니라 표본 개수-1 (n-1)개로 나누고 있다. 도대체 왜 n-1로 나누는 것일까?
Answer1) 단순히 표본내부의 데이터들이 평균으로부터 떨어진 거리를 나타내고자 한다면 n으로 나누는 것이 맞겠지만, 해당 수식은 표본으로부터 모집단을 추정하고자 하는 추정량이다. 즉, 표본 자체 통계량이 중요한 것은 아니고 얼마나 모집단 파라미터를 잘 추정하느냐가 중요하다.
2. n으로 나눈다면 무엇이 문제인가?
만약, 표준편차의 분산 추정량을 n-1이 아니라 n으로 나눈다면 어떤 일이 발생하길래?
Answer2) 이에 대한 답은 단순하다 편향 추정이 발생한다 정확히 여기서는 과소추정이 된다. 즉, 본래의 모집단의 분산보다 작게 추정된다는 의미이다.
3. 왜 과소추정(편향 추정)이 일어나는데?
왜 표본 개수 그대로 나누면 과소추정(편향 추정)이 일어나는데?\
Answer3)

* 이 대답은 어느정도 나의 의견과 생각이 들어가 있다.
위의 그림 1은 모집단에서 샘플링하여 얻은 표본 분포를 나타낸다. 이때, 모집단에서 "Interval 1"이라고 표시된 구간에서 샘플링될 확률이 높을 것이다. 이 경우, 샘플링된 분포는 모집단 내에서 밀집된 구간을 더 많이 반영하게 된다. 즉, 모집단의 전체 분포에 비해 샘플링된 분포는 더 조밀해질수 있다. 결과적으로, 표본평균의 분포는 모집단의 분포보다 더 조밀할 것이고 이것은 표본의 개수로 나누어 분산을 그대로 구할경우 과소추정(편향 추정)으로 이어질 것을 암시한다.
따라서, 표본 분산을 이용해 모집단 분산을 추정할 때는 보정이 필요하다. 이를 위해 단순히 표본 크기 n으로 나누는 대신, n−1로 나누어 분산을 보정한다.
n-1을 나눈다는 의미
사실상, n이 무한히 커질수록 표본이 모집단에 가까워지기 때문에 n−1로 나눌 필요 없이 n(거의 N)으로 나누어도 충분하다. n이 커질수록 n−1은 n에 근접하게 되어 1의 영향은 거의 없어지지만, n이 작을 때는 n에서 1을 뺀 차이가 상대적으로 커져 그 영향력이 더 크게 작용한다. 즉, n-1이 적절해 보인다. 하지만, 여기서 또 아래 4번과 같은 의문이 들수 있다.
4. 수학적으로 증명은 되었는가?
과소추정이 일어나서 n-1로 보정하는건 알겠는데, 그렇다고 해서 왜 n-1로 나눠야 하는건지 이해가 가지 않는다. 이 부분에 대한 증명은 되어 있는가?
Answer4) 이에 대한 수학적 증명은 아래와 같다.

위의 수식과 같이 증명되어 있다. 3번째 질문에서 생각해봤듯이 직관적인 이해뿐만 아니라 수학적으로 증명되어 있음을 확인 할 수 있다.
5. n-1이 자유도라고 하는데 자유도의 개념은 무엇인가?
n-1로 나눈것을 자유도 degree of freedom이라고 부르는 것을 많이 봤을 거다. 그런데 자유도가 무엇인지에 대한 개념부터 알아보도록 하자.
Answer5)
통계학에서의 자유도란?
우리가 어떤 추정값을 계산할 때 실제로 독립적으로 변동할 수 있는 데이터 포인트의 수라고 설명하고 있다.
위의 말은 무슨 말일지 생각해보도록 하자.
위의 그림3에서처럼 모집단에서 표본 5개를 추출했다고 해보자. 그리고 표본의 평균이 20이라고 해보자.
X1은 어떤 숫자가 추출되어야 할까?
모집단 분포에서 랜덤하게 추출될 수 있다. 특정 값으로 고정되지 않으며, 확률 변수로서 독립적으로 존재한다. 다르게 표현하면 모집단 분포로부터 랜덤하게 샘플링이 가능하다. (어떠한 숫자가 들어가도 상관이 없다)
X2는 어떤 숫자가 추출되어야 할까?
X2또한 X1과 마찬가지로 모집단 분포에 따라 자유롭게 샘플링된다.
이와 마찬가지로 X3, X4 또한 독립적으로 모집단에서 추출된다. 이 데이터들은 자유롭게 변동될 수 있다.
그런데, X5는 어떤 숫자가 추출되어야 할까?
마지막 데이터 포인트 는 모집단으로부터 랜덤 샘플링이 되는 것이 아니라, X1부터 X4까지의 값들에 따라 자동으로 고정된다. 표본의 평균이 20이라는 제약이 있기 때문이다. 따라서 마지막 데이터 포인트인 X5는 자유롭게 결정될 수 없고, 나머지 값들에 따라 자동으로 고정된다.
예를 들어, X1 = 25 , X2 = 10 , X3 = 15 , X4 = 40이라는 값이 나왔다면, 표본 평균이 20이 되기 위해 X5는 10으로 고정된다. 이처럼 마지막 데이터는 더 이상 랜덤하게 결정될 수 없고, 고정된 값이 된다.
일반화
n개의 데이터를 추출했을 때, n-1개의 데이터는 자유롭게, 랜덤하게 추출되지만 마지막 n번째 데이터는 표본 평균의 제약에 의해, 나머지 n-1개의 값에 의해 결정된다. 여기서 독립적으로 변동할 수 있는 데이터 포인트의 수는 n-1이며, 이를 자유도라고 한다.
(여담) 기계공학에서의 자유도?
자유도는 비단 통계학에서만 통용되는 개념은 아니다. 일반적으로 기구학에서 움직임을 묘사할때 예를 들어 x, y, z축 3개의 축으로 움직일수 있다고 했을때 DOF(Degree Of Freedom)을 3이라고 한다. 만약, x에서의 병진운동이 제한됐을때, y, z축으로만 움직일수 있기때문에 DOF는 2라한다. 이와 마찬가지로 자유도의 본질적인 개념은 변화가 가능한 요소들의 개수를 의미한다.
6. 분산을 구할때 도대체 자유도의 의미는 무엇인가? 왜 자유도로 나누게 되는 것인가? (본질)
그렇다면, 자유도의 관점에서 모분산 추정량과 무슨 관계가 있는것인가?
Answer5) 위에서 우리는 표본에서 추정할때 n-1로 나누는 당위성은 과소추정(편향 추정)을 보정하기 위함이라고 위에서 설명했다. 이번에는, 자유도의 관점에서 분산을 설명해보고자 한다.
질문의 흐름 (Story)
1. 여기서 원론적인 질문을 할 수 있다. 왜 표본의 평균이 고정되어 있어야 하는가? 샘플링을 하다 보면 표본 평균이 20이 아니라 25가 될 수도 있을 텐데, 고정시키는 이유를 이해하기 어려울 수 있다.
모수 통계에서는 내가 샘플링한 데이터를 기준으로 모수를 추정하기때문에 항상 표본 데이터를 기준으로 한다. 만약 데이터를 더 샘플링한다면, 새로운 샘플을 포함하여 표본 평균을 계산하고 표본 분산을 재추정하면 된다.
샘플링을 할 때마다 표본 평균이 달라질 수 있는 것은 맞지만, 우리는 이미 샘플링이 완료된 상태에서 모수를 추정하는 상황이라고 이해하면 된다. 표본 평균이 고정되어 있는 이유이다.
2. 이미 샘플링이 완료되었다고 했으면서, 표본 평균은 고정되어 있는데 분산추정에서는 n-1개의 데이터가 변동성이 있다니 이게 무슨 모순된 말이냐?
분산이라는 통계량 자체가 평균으로부터 데이터들이 얼마만큼 떨어져 있는지를 표현하기 이전에, 불확실성을 정량화 하기 위해 나온 기초 통계량임을 상기시켜보자.
본론을 읽기전에 아래 불확실성에 대한 글을 읽기를 권장드립니다.
'데이터분석-통계/통계학' 카테고리의 글 목록
다양한 공학분야, 후기들에 대한 내용을 다루고 있는 블로그입니다
taehyuklee.tistory.com
착각 포인트
평균으로부터 떨어진 거리개념에 집중하다보면, "당연히 n개에 대해서 거리 계산했으니까 n으로 나눠야 하는데?"라는 의문에 갇혀 나오지 못하게 된다. 다시 한 번 말하지만, 분산의 거리의 평균이라는는 직관은 결과적인 얘기이고, 불확실성이 우선되는 개념이다. 불확실성을 따질려다보니 평균과 각 데이터 포인트 사이의 차이를 계산하게 된 것이고, 그 결과 각 데이터들이 평균으로 부터 떨어진 거리 개념이 나온 것이다.
생각의 포인트

위의 그림을 기준으로 생각해보길 바란다. 표본평균은 이미 정해져 있다고 생각하면 여기서 변동성이 있는건 n-1개밖에 없다. 다시 말하자면, n-1개만 모집단으로부터 랜덤 추출이 가능하며 나머지 한개는 n-1개에 따라 고정되므로, 모집단의 분포를 따르지 않는다. n-1개가 정해진 시점에서 확률이 존재하지 않는다. 그렇기에 전체 데이터에 대해 변동성을 표현하는 (데이터 - 표본평균)의 제곱에다 변동성을 띄는 데이터 n-1개를 나누면 대표값인 분산이라는 통계량이 발생하게 된다. 이것이 분산을 평균 거리 이전에 좀 더 본질적으로 접근하는 생각이다.
3. 모집단에서도 N-1개까지 자유도가 있으니, 분산은 N이 아니라 N-1으로 나눠야 하는거 아닌가?
모집단에서는 이미 Exact한 값을 기준으로 모수를 계산하기때문에 확률이 존재하지 않는다 (추정이 아니라 계산). 하지만,표본에서는 아직까지 확률이란게 존재하기 때문에 자유도가 존재한다.
참고 자료
1. 12 Math - Youtube - https://www.youtube.com/watch?v=TckEM-6tdrc&t=799s
2. 통계학 입문 - 자유아카데미 (전공서적)
3. 학교 수업 자료 - 자료분석개론
4. 나의 생각 및 글 정리 (feat GPT)
'데이터분석-통계 > 통계학의 본질 이론' 카테고리의 다른 글
| 중심극한 정리 (Central Limit Theorem) : 정의 및 실험 & 용도 (2) | 2024.11.03 |
|---|---|
| 평균치 검정 : t검정 [One, Two(Student's & Welch's), Paired Samples t-test] (0) | 2024.11.03 |
| 신뢰 구간(Confidence Interval)의미와 직관 그리고 오해 : 구간 추정, 신뢰 수준, 오차 한계, 신뢰도 95%의 개념 (5) | 2024.10.13 |
| 가설검정 이해: 검정통계량, 귀무가설, 대립가설, p-value, 유의수준 (significance level), 임계값 (critical value) 개념 정리 (본질) (1) | 2024.10.06 |
| 불확실성, 변동성, 분산 (feat 확률의 본질) (0) | 2024.09.30 |



