당시 네이버 블로그에 후기를 남긴 적이 있지만, 과거를 기록하기 위해 티스토리 블로그로 글을 다듬어 옮겨본다.
학부생시절 2019년 11월 15일 대한 기계학회 (KSME)에서 주최하는 유체경진대회에 논문을 투고하여 금상을 수상했다.
* 해당 연구는 4학년 졸업논문(학부연구) 주제이기도 하다. (학부 졸업 논문 포스터 링크)

연구주제: 신경회로망을 통한 초미세먼지 농도 예측
초미세먼지(PM2.5)를 설명할 수 있는 변수로 기상, 대기질 데이터를 수집한 후, 이 데이터를 가공하고 최적화한다. 가공된 데이터를 기반으로, PM2.5 농도에 대한 예측 모델을 지도 학습(Supervised Learning)으로 구축하여 6시간 후와 12시간 후의 농도를 예측하는 것을 목표로 한다.
이미 미세먼지 농도를 예측하는 시스템이 존재하는데 굳이 할 필요가 있나?
위와 같은 의문을 가질수 있다. 결론적으로는 이미 농도에 대해 예측하는 시스템을 가지고 있고 어느정도 신뢰수준이상으로 잘 맞추고 있다. 하지만 기존에 있는 것은 계산을 수만번 반복하여 얻어내는 결과들로써 계산하는데 많은 시간(1달이상의 계산도 많다)과 상당히 큰 재원(물질적 돈, 컴퓨터 등)이 필요하다.
하지만, 위 연구에서 신경회로망을 학습시키는데는 최소한의 컴퓨터 재원과 10만개정도의 데이터를 가공하고 학습 시켜 완성했다. 즉, 상황에 따라 계산량을 상당히 많이 줄일수 있다는 특 장점이 있으며, 실제로 고려되지 않는 것들도 실제 측정 데이터 속에 녹아 들어 있어 때에 따라 좀 더 많은 설명력을 가질 것이 기대 효과였다.
한 가지 결과를 제시하자면, 실제 농도는 빨간색으로 표시되고, AI(신경회로망)로 예측한 농도는 초록색이다. 경향성은 어느 정도 잘 맞추고 있는 것 같다라고 2019년의 나는 판단했었다. 그러나 이후 2021년 두 번째 연구 주제에서 시간 밀림(time lag) 현상이 해당 결과에 존재한다는 사실이 밝혀졌다. 이 현상을 강화 학습을 통해 보정하려는 시도를 통해 어느 정도 완화할 수 있었던 경험이 있다.
당시에는 99%정확한 값을 예측하기보다 그 경향을 일정 수준 이상의 정확도로 빠르게 예측하는 것에 초점을 맞추고 있다라고 생각했지만, time lag현상때문에 아예 예측이 틀렸음을 2021년 연구를 통해 알 수 있었다.
[2019년 당시의 다짐 - 당시의 생각이기때문에 글귀 그대로 남겨둔다]
앞으로는 다상유동이나 전통유체 등 (물리적 세계)에서 AI가 얼마나 유효할지에 대해서 기대하고 있으며 '통계학'을 계속해서 공부하고 있습니다. 특히 앞으로는 모수통계학보다는 베이지안 통계학을 기반으로 하는 학문들이 많아지고 있기때문에 베이지안 통계학을 공부해 보시는 것을 추천합니다. (이후 통계학 공부를 진짜 많이 했다)
기계공학부생 그리고 환경공학부 학생으로서 할수 있는 좋은 경험이었으며 앞으로 학부를 졸업한 이후 대학원생활을 하면서도 이번 경험을 살려 많은 연구를 하고 최종적으로 여러 아이디어를 생각해 내고 최선을 다해 기술을 개발하는 것을 목표로 해보겠습니다.
*2019년의 내 생각에 다시 한 번 박수를 보낸다. 지금은 회사원이 되어 있는데 여전히 저 꿈은 못버린듯 하다.
자 여기서부터는 현재의 내가(2024년 10월 09일) 이어서 쓰는 글이다. 당시 데이터 가공법에 대해서 공유 하고자한다.
A. Data Collection (데이터 수집)
pm2.5, pm10, NOx, SOx와 같은 대기질 데이터들은 Air Korea에서 기상데이터는 기상자료개방포털에서 2008년부터 2018년 3분기까지 데이터를 수집하여 총 32개의 변수 (Columns) 94225개의 관측치(Rows)를 수집했다.
B. Data Process (데이터 가공)
(Step 1) 결핍 변수 제거 : Removal of Deficiency data
수집된 데이터중 Not Available으로 값이 비어 있는 데이터 50% 이상인 변수(Columns)에 관해서는 삭제. 추후에 Imputation시 데이터 오염을 시킬 것으로 판단했다.
(Step 2) 설명 변수 선택 : AIC (Akaike Information Crietrion) - Stepwise selection method
Step 1을 거치고 남은 변수(Column)들 중에서, AIC 모델을 활용하여 타겟 변수인 pm2.5에 대한 설명력이 낮은 변수를 제거한다. 결과적으로 Middle and low cloud와 Sunshine hour 두 변수가 제거되었고, 21개 변수가 남게 되었다. 그러나 여전히 변수 간의 독립성은 보장되지 않고 있음을 염두에 두고 있었다.
(Step 3) 독립변수 선택 (Check of Independency) : VIF (Variance Inflation Factor)
설명 변수간 독립성을 보장해주는 것이 모델의 기본 가정이므로 Variance Inflation Factor와 역학적 이론을 통해 설명변수간의 독립성을 보장해준다.
VIF 값은 통계적으로 변수 간 상관관계가 높다는 결과만을 제공하며, 내부적으로 변수를 제거하는 과정은 공학적 지식을 통해 이루어져야 한다. 예를 들어, 상대 습도(Relative Humidity)와 증기압(Vapor Pressure)의 경우, 그림 3의 오른쪽을 보면 상대 습도가 증기압을 통해 정의된다는 것을 확인할 수 있다. 이럴 때는 더 근본적인 변수인 증기압을 선택하는 것이 옳다고 판단된다. 이러한 판단을 바탕으로 독립 변수를 선택해 나갔다.
(Step 4) 최종 선택된 변수들 정리 (Selected Variables)
13개의 변수 리스트
pm10, Visibility, SO2, CO, NO2, Vapor Pressure, O3, Sea level pressure, Temperature, Solar radiation, Total cloudy, Wind direction, Wind speed
위의 3 과정을 거치며 pm2.5(초미세먼지)를 설명하기 위한 설명 변수 13개가 선정되었다.
(Step 5) 결측치 보정 (Imputation)
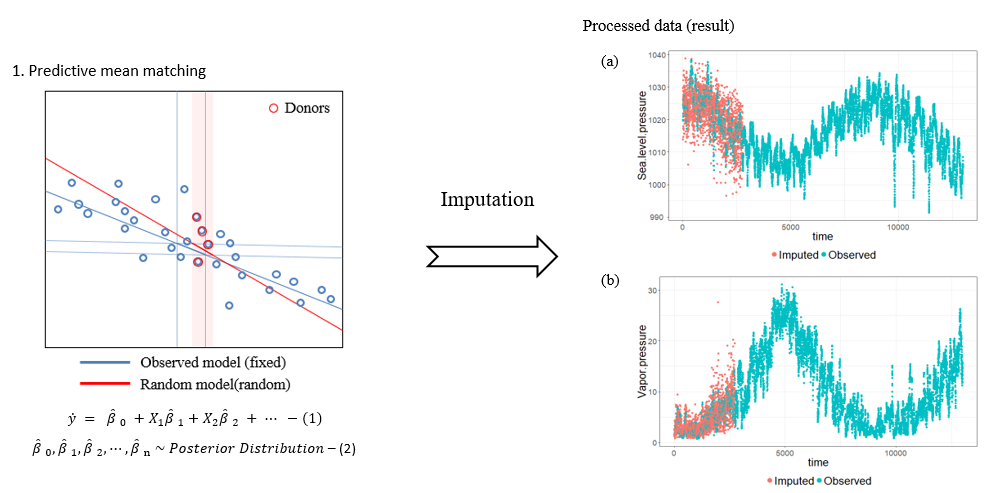
Step 1에서는 50% 이상의 결측치가 있는 변수만 제거했으며, 나머지 변수들에도 NA 값이 존재하고 있다. 따라서 최종 선택된 13개 변수에 대해서는 Predictive Mean Matching (PPM) 방법을 사용하여 NA 값을 채워 넣었다. 우측의 그림 (a)와 (b)는 채워진 값에 대한 경향을 보여준다. 빨간 점은 Imputation된 값이며, 초록 점은 기존에 측정된 값이다.
참고로, Deterministic Linear Model과 Stochastic Linear Model을 사용하여 Imputation을 시도했으나 비물리적인 값이 나와서 사용할 수 없었다.
위의 5개 과정을 거치면서 데이터 가공을 마쳤고, 모델 학습을 위한 준비를 완료했다.
C. Model Training (학습)
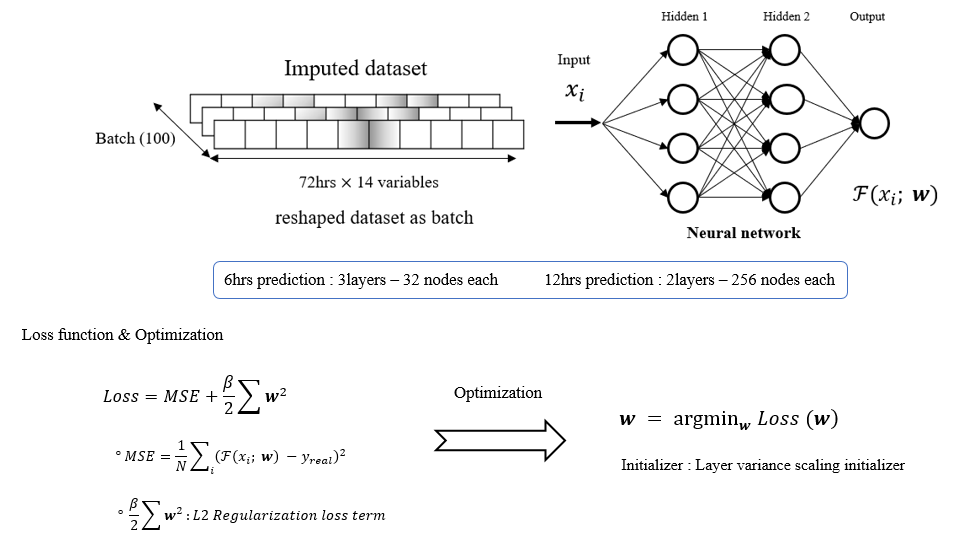
앞서 가공된 데이터를 통해서 예측 모델을 학습한다. 기본 ANN모델에 Window Learning 기법으로 학습 시켰다.
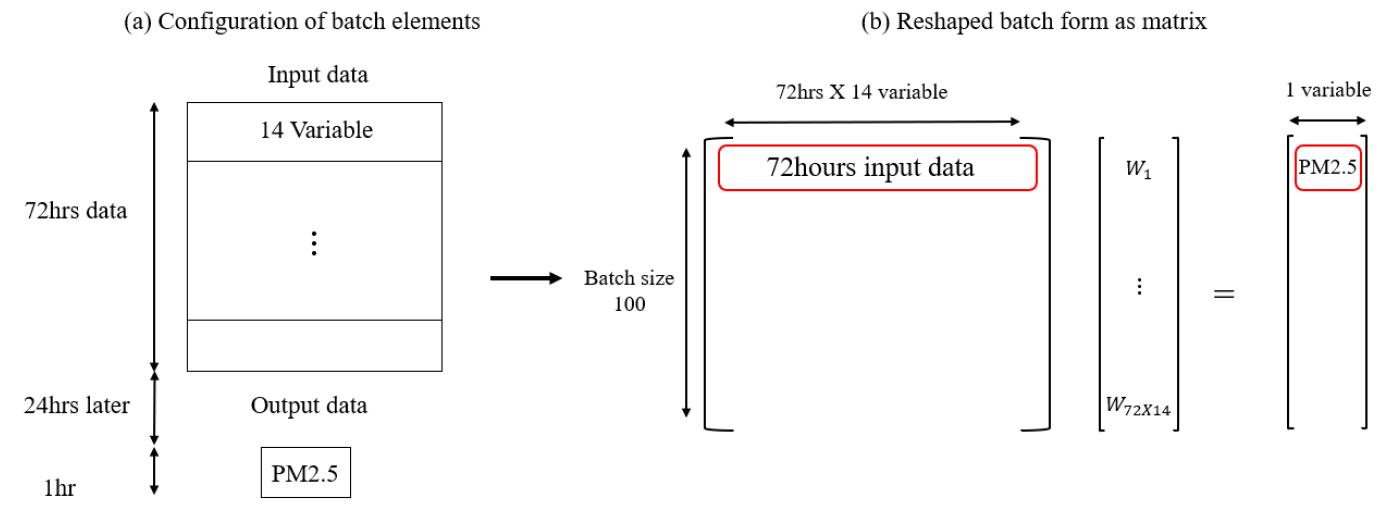
그림 6은 이전 72시간의 데이터를 사용해 6시간 후, 12시간 후, 24시간 후를 예측하기 위해 배치를 어떻게 구성했는지를 보여주고 있다. 24시간 이후의 1시간 예측을 위해, 72시간 동안의 pm2.5를 포함한 14개의 변수를 재구성(Reshape)하여 입력 데이터로 변환한 과정이다. 이때 배치는 100개씩 설정되어 있다.
D. Training & Test Result (학습후 테스트 결과)
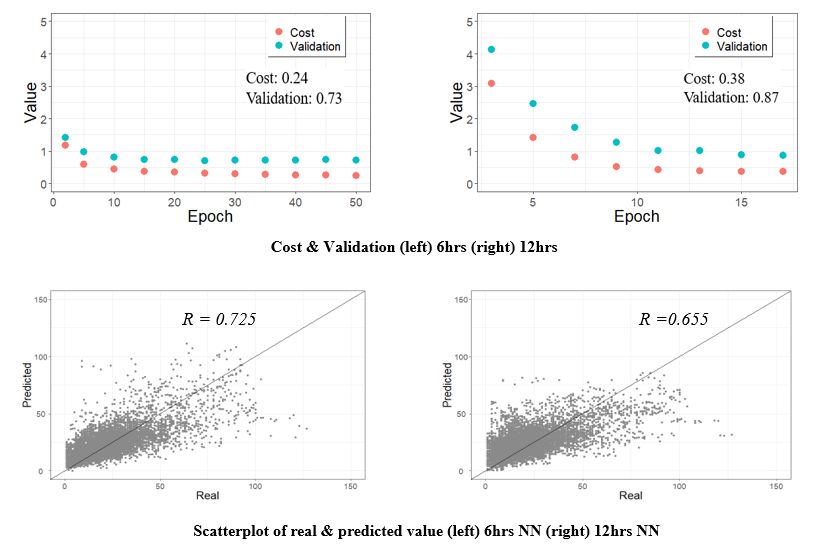
당시 학습 정도는 Cost 및 Validation값을 통해 확인했다. 또한 테스트 결과를 산점도(Scatter Plot)로 제시했다. 고농도 예측으로 갈수록 모델 성능이 더욱 저하되는 것을 확인할 수 있었다. 그리고 지금 생각해보면, 산점도는 시간 밀림(time lag) 현상을 포착하지도 못한다.
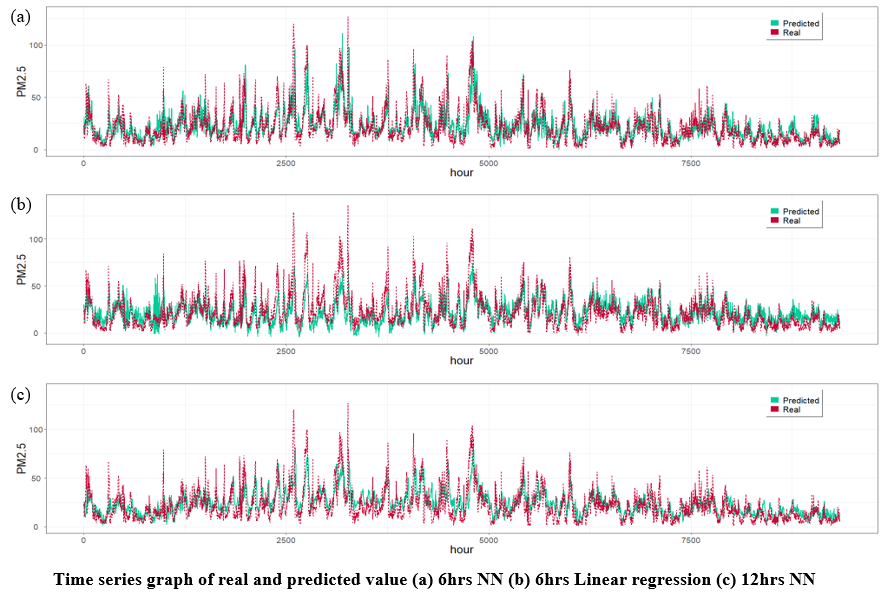
2019년 당시에는 해당 결과가 완전히 틀렸다는 사실을 알지 못했다. 전체적인 그림을 봤을 때, 특히 6시간 예측 모델은 잘 맞는 것처럼 보였기 때문이다. 그러나 현재는 앞서 언급한 시간 밀림(time lag) 현상으로 인해 이 결과는 사실상 틀렸음을 알 수 있다. 과정이 좋았던 건지, 발표력이 좋았던 건지 모르겠지만, 잘못된 결과로 당당하게 교수님들을 속이고? 수상 했다. 그것도 금상 ^^
이후 스토리 2021년 대학원에서
이후 대학원에서 강화 학습(Reinforcement Learning)을 통해 유클리드 거리(Euclidean distance)뿐만 아니라 각도(angle)를 고려하여 시간 밀림(time lag) 현상을 어느 정도 보완했다 : 효과를 봤다. 그러나 절대적인 시간이 부족했기에 (메인 연구 진행하느라) 결국 이를 마무리하지 못하고 졸업했다.
'후기 > 컨퍼런스 후기' 카테고리의 다른 글
| [Summit] AWS summit 후기 (1) | 2024.06.13 |
|---|
